 This post is one of a series of blog posts from the first ONA class of MJ Bear Fellows describing their experiences, projects and sharing their knowledge with the ONA community. Fellow Lucas Timmons is a data journalist and web producer for The Edmonton Journal in Edmonton, Alberta, Canada.
This post is one of a series of blog posts from the first ONA class of MJ Bear Fellows describing their experiences, projects and sharing their knowledge with the ONA community. Fellow Lucas Timmons is a data journalist and web producer for The Edmonton Journal in Edmonton, Alberta, Canada.
Sometimes when dealing with data, you’re given incredibly useless PDF files instead of databases and csv files. When a government agency gives you a database but refuses to give you a spreadsheet or .csv file, it could be in the hopes that the data will be too difficult and time-consuming to use to tell a story. The agency might be hoping you just forget it because it’s too difficult to work with. However, there is a tool that can help you liberate that data.
You can use Pdftotext to convert PDF files into plain text files. This makes them much easier to manipulate and work with.
Pdftotext uses part of the Xpdf software created and licensed under the GPL by Glyph & Cog, LLC. The Xpdf project is a PDF viewer, but also includes the text extractor and a pdf-to-PostScript converter. Pdftotext is the extractor.
Xpdf can be downloaded here. If you are uncomfortable working in the command line, you will want the precompiled binary. For those using Mac OS X, Carsten Blüm has provided a simple installer for the extractor tool only. You can download an installer here.
Usage
Windows:
Once you have downloaded the precompiled binary files, extract them to somewhere on your computer. Go into the directory and navigate into either the 32bit or 64bit folder, based on which version of Windows you are running. You should see seven .exe files. Remember this location; you should be able to see it in the address bar of the folder you are in.

The address bar location of the .exe files.
Open the command prompt. The shortcut is usually in the Start menu. Once it is open, you will need to navigate to the folder you had open in Windows Explorer. Remember the directory? Good. Type “dir” and press Enter to get a file listing of the directory you are in. Type “cd directoryname” and press Enter to switch to that directory. If you need to move out a layer, type “cd ..” and press enter. Use this to navigate to where you have your PDF file saved. Continue with the directions below.
OS X:
Once you have installed Pdftotext, it will be available for use in Terminal view. Launch Terminal and let it log in. You now need to navigate to the directory Where the PDF file you want to convert is stored. Type “ls” and press Enter to get a file listing of the directory you are in. Type “cd directoryname” and press Enter to switch to that directory. If you need to move out a layer type “cd ..” and press enter. Use this to navigate to where you have your PDF file saved. Continue with the directions below.
For both Windows and OS X operating systems:
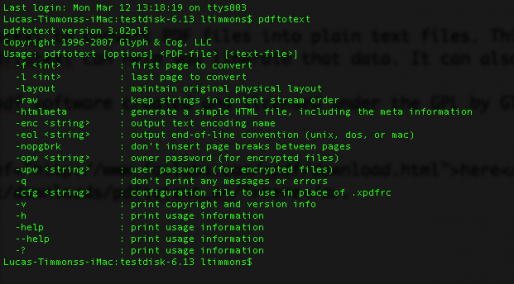
The pdftotext manpage.
Once you are in the right directory, type “pdftotext” and press Enter. It will bring up the manpage for the tool. This will show you how to use the tool and what commands can be passed to the tool.
Here is a listing:
- -f int : first page to convert
- -l int : last page to convert
- -layout : maintain original physical layout
- -raw : keep strings in content stream order
- -htmlmeta : generate a simple HTML file, including the meta information
- -enc string : output text encoding name
- -eol string : output end-of-line convention (unix, dos, or mac)
- -nopgbrk : don’t insert page breaks between pages
- -opw string : owner password (for encrypted files)
- -upw string : user password (for encrypted files)
- -q : don’t print any messages or errors
- -cfg string : configuration file to use in place of .xpdfrc
- -v : print copyright and version info
- -h : print usage information
- -help : print usage information
- –help : print usage information
- -? : print usage information
The most basic usage would be “pdftotext filename.pdf”. That would create a text file with the same name as the PDF file, filled with the text from the pdf file. You can add extra commands if you want to change how the extractor works. “pdftotext filename.pdf -layout” would attempt to keep the text in a similar layout to the PDF file. “pdftotext filename.pdf -f 1 -l 10” would extract the text only from pages 1 to 10.
Common problems
Installing pdftotext on OS X asks for a password
Because pdftotext modifies the /usr/local directory, you may need to be a privileged user. If that’s the case, you will need an administrator password when trying to install.
My output text is blank!
The text inside your PDF file has been stored as an image and not as text. A solution that might be successful is to open the PDF file in Adobe Acrobat and run the PDF through and OCR scan. Once that is done, save the PDF and try running pdftotext again.
My PDF needs a password
Some people and groups who create PDFs sometimes password-protect them. Pdftotext will not remove this feature. If you’re clever, you can find a way to print the PDF file to a PDF printer, thereby saving it as an image. You can then try with pdftotext. The output will most likely be blank. If that’s the case, try doing what was suggested under “My output text is blank!” If that doesn’t work, try an appeal to the PDF’s creator. He or she might be able to help you.
Slide photo is by Ken Teegardin via Flickr.